本文继续以Avazu-CTR赛题为背景,尝试采用FM(Factorization Machine,因子分解机)及FFM(Field-aware Factorization Machine,场感知因子分解机)来进行CTR预估任务。

本文的源码托管于我的Github:PnYuan - Kaggle_CTR,欢迎查看交流。
1.概念
商用推荐场景中的CTR预估工作易面临大规模稀疏数据的挑战。因子分解机( Factorization Machine, 简称FM )模型的引入正对于此,其通过对参数矩阵的低秩分解,来解决高维训练的低效问题。这里,首先示例性地介绍数据稀疏和特征组合的相关内容,然后引出FM模型及其拓展形式FFM。
1.1.数据稀疏
设用于CTR预估的原始数据如下表所示(表1):
| 时间戳(time) | 用户性别(sex) | 网站类型(st) | 广告类型(at) | 是否点击(clicked?) |
|---|---|---|---|---|
| 16102206 | male | 1 | 2 | 1 |
| 16110218 | - | 3 | 1 | 0 |
| 16110222 | female | - | 6 | 1 |
类似数据中常包含大量离散型特征(categorical features),如上表中的特征“用户性别,网站类型”等,独热编码(One-hot)常被用于此类特征的预处理。设经过编码转换后的新数据如下表所示(表2):
| time | sex_1 | sex_2 | st_1 | st_2 | st_3 | … | at_1 | at_2 | at_3 | … | clicked? |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 16102206 | 1 | 0 | 1 | 0 | 0 | … | 0 | 1 | 0 | … | 1 |
| 16110218 | - | - | 0 | 0 | 1 | … | 1 | 0 | 0 | … | 0 |
| 16110222 | 0 | 1 | - | - | - | … | 0 | 0 | 0 | … | 1 |
上表2所示的数据往往规模庞大且稀疏,其高特征维度和低信息密度,严重制约着模型训练效率。
1.2.特征组合
原始特征通过组合可以构成组合特征,进行合理的特征组合有助于提升特征的表达能力,增强模型效果。如上表2中特征的组合 sex_1(男性) × at_3(球类广告),sex_2(女性) × at_1(瑜伽广告) 等等。以2-阶组合为例,套用多项式模型可写作:
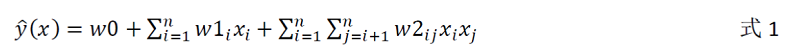
式中,n为原始特征数,w0,w1,w2是各阶参数,其中对w2的训练即对应于2阶特征组合的学习。
1.3.FM
在数据稀疏场景下,采用线性模型(如式1)对组合特征进行学习将面临严重困难,其原因之一是:组合参数w2_ij的学习当x_i≠0 && x_j≠0才有效,而稀疏数据中满足要求的样本数极少甚至没有、
FM模型的引入较好的解决了上述问题,其运用因子分解的思想,将原始参数矩阵W2按照 W2 = V·VT 进行改写,如下式所示:
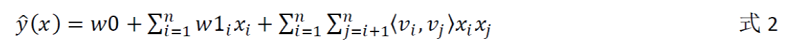
式中:V∈Rn×k,v_i(k维向量)对应于特征x_i的embedding表示,<,>对应于向量内积。上式二阶项可进一步改写如下:
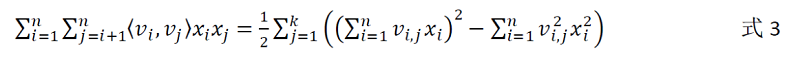
对式3分析可知:
一方面,参数
v_i只与x_i有关,使得FM在稀疏数据下的训练难度远低于多项式模型;另一方面,FM模型的参数更新可采用梯度下降法进行闭式求解,其时间复杂度为
O(kn)(线性时间复杂度),远低于多项式模型稠密参数矩阵W的O(n2)计算复杂度。
FM模型还可以拓展至n-阶组合项,这里不作赘述。
FM的特点可简要总结如下:
FM模型通过因子分解,实现了特征空间的解耦,完成了从高维特征空间到低维embedding空间的降维简化,大大降低了在稀疏数据场景下的组合特征学习难度,同时有助于提高模型泛化能力;
FM模型具有线性的训练时耗复杂度,算法易轻量高效地实现;
FM输入不敏感,模型的泛化迁移能力强;
1.4.FFM
FFM模型在FM模型的基础上引入了场(field)的概念,即:具有相同性质或类型的特征属于同一个场。一般地,由同一个categorical特征经过One-hot编码所生成的特征都可被视为属于同一个field,如前表2中st_1、st_2...均视为属于同一个field,即表1中的st。
这里仍以二阶组合参数为例,给出FFM与FM的直观区别如下图所示:
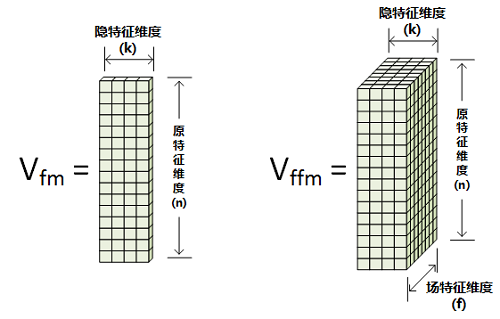
可见,在FM模型扩展至FFM模型时,原始特征的低维嵌入空间维度由n×k变为n×k×f。其中的f表示场特征维度。对于每个特征x_i,需学习的参数为其相对于每个field的隐特征向量v_if。写出FFM表达式如下:
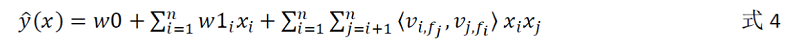
式中,f_i为x_i所属field。从此可见,FFM将特征所属field的信息加入到学习之中,实现场感知(field-aware),进一步提升了组合组合的表达能力。由于上式中内积项<,>同时与下标i,j有关,其计算复杂度为O(kn2),轻量性不如FM模型。
2.实验
此处采用与前上文CTR预估(LR)相同的特征数据集(12个原始特征和2M条训练样本,经过长尾简化)。FM/FFM模型的开发实现基于xlearn软件包。为运用数据,还需将原始数据转换为xlearn中的模型所支持的格式(如libffm格式)。
经过建模、训练、参数调节等工作之后,将训练好的模型用于测试集预测,得出Kaggle评分如下:
FM
- Private Score: 0.4070471(71%) - Public Score: 0.4087310(71%)FFM
- Private Score: 0.4037954(69%) - Public Score: 0.4056881(70%)
3.小结
本文继续围绕Avazu-CTR预估任务,研究了FM-based和FFM-based实现方案,相继完成了:
- FM/FFM模型概念;
- 基于FM/FFM的CTR预估实验;
等内容。从过程和结果可以看出,FM在大规模稀疏数据场景下具有不错的效果。